|
My name is Jie He. I am currently a fourth-year Ph.D. student at University of Edinburgh. I am fortunately advised by Prof. Jeff Pan and Prof. Victor Gutierrez Basulto. My research is generously supported by Edinburgh Doctoral College and 2024 Apple Schaolars in AI/ML Fellowships. Before I join UoE, I was fortunated to work at TJU-NLP since Sept. 2019, advised by Prof. Deyi Xiong and advised by Prof. Qun Liu. Also, I worked as an intern under the supervision of Prof. Pasquale Minervini in Fall 2021. I obtained my M.S. degree in Computer Science Department at Tianjin University and my bachelor's degree in Software College, Shandong University. I am actively looking for PhD Intern position starting from 2025. Email / CV / Google Scholar / Twitter / Github |

|
|
My primary research interests lie in natural language processing (NLP), especially in commonsense reasoning and grammactical error correction. Currently, my research are driven by two goals: Reasoning: Build an AI system that taps into intrinsic knowledge and uses extrinsic knowledge for logical reasoning. Generalization: Design a creative AI model that can use existing experience to solve new problems. |
|
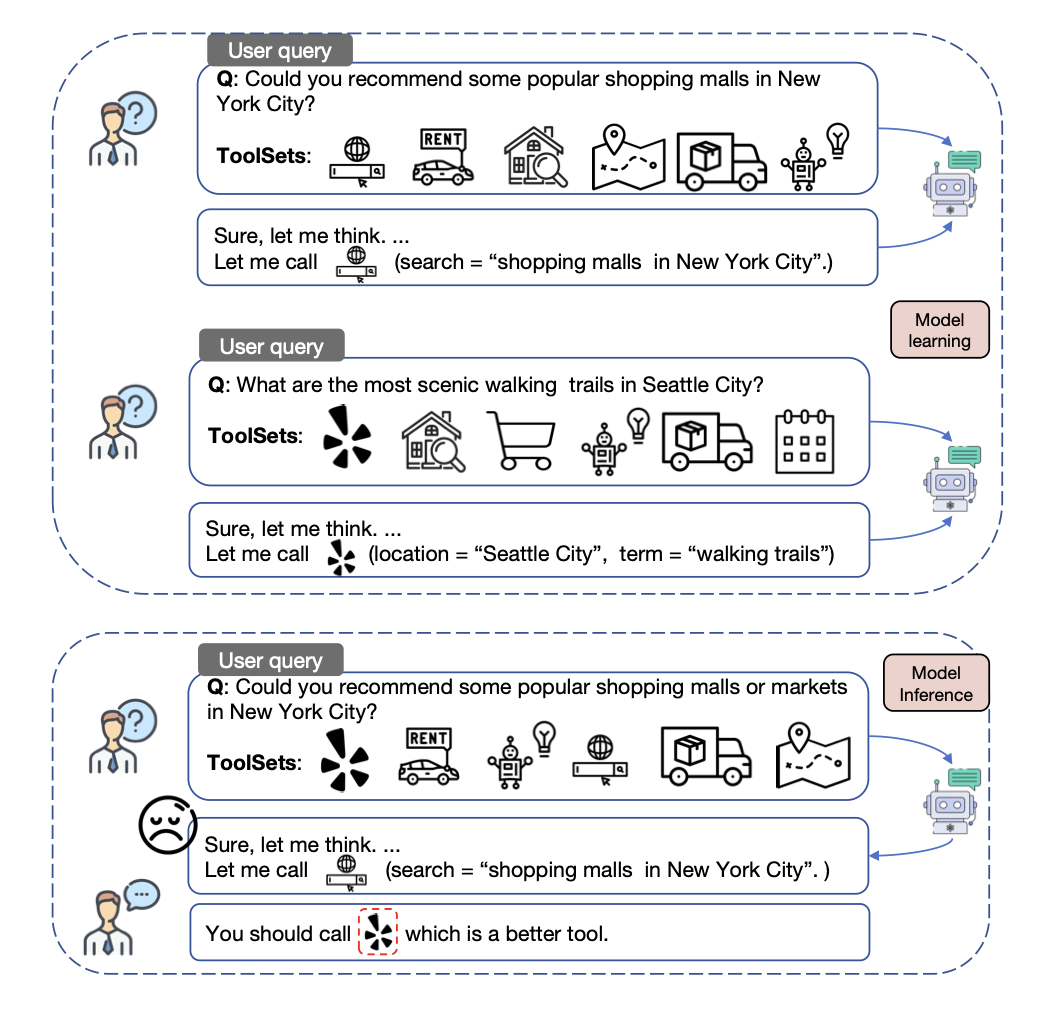
Jie He, Jennifer Neville, Mengting Wan, Longqi Yang, Hui Liu, Xiaofeng Xu, Xia Song, Jeff Z. Pan, Pei Zhou ACL 2025 findings [paper]Large Language Models (LLMs) can enhance their capabilities as AI assistants by integrating external tools, allowing them to access a wider range of information. While recent LLMs are typically fine-tuned with tool usage examples during supervised fine-tuning (SFT), questions remain about their ability to develop robust tool-usage skills and can effectively generalize to unseen queries and tools. In this work, we present GenTool, a novel training framework that prepares LLMs for diverse generalization challenges in tool utilization. Our approach addresses two fundamental dimensions critical for real-world applications: Zero-to-One Generalization, enabling the model to address queries initially lacking a suitable tool by adopting and utilizing one when it becomes available, and Weak-to-Strong Generalization, allowing models to leverage enhanced versions of existing tools to solve queries. To achieve this, we develop synthetic training data simulating these two dimensions of tool usage and introduce a two-stage fine-tuning approach: optimizing tool ranking, then refining tool selection. Through extensive experiments across four generalization scenarios, we demonstrate that our method significantly enhances the tool-usage capabilities of LLMs ranging from 1B to 8B parameters, achieving performance that surpasses GPT-4o. Furthermore, our analysis also provides valuable insights into the challenges LLMs encounter in tool generalization. |
|
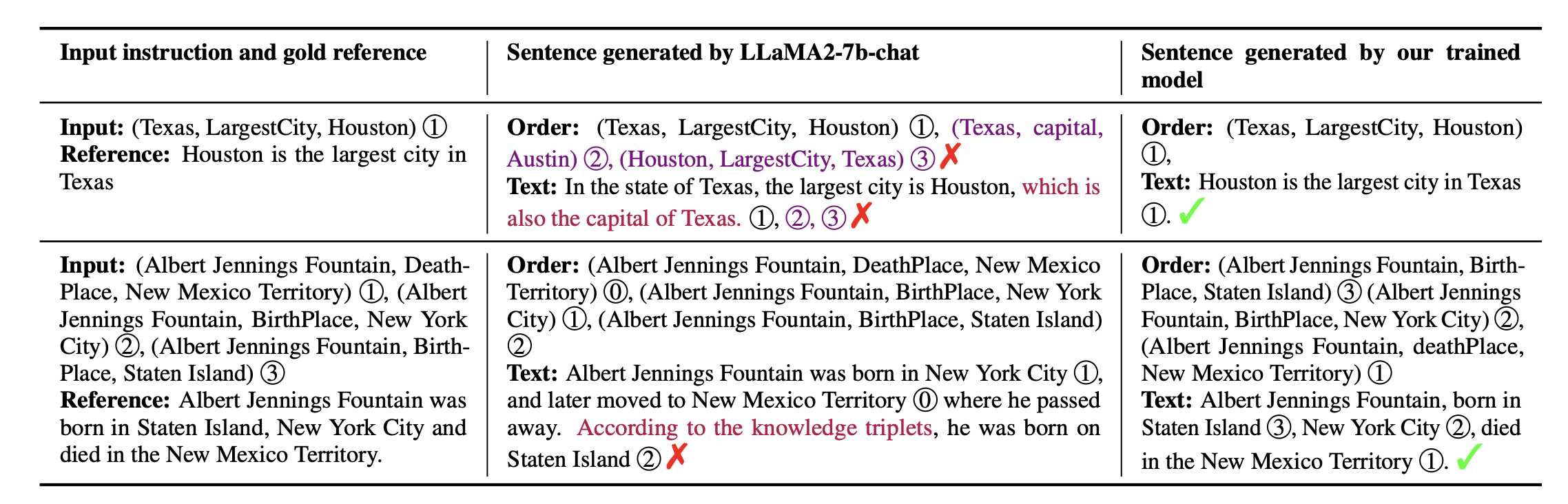
Jie He* , Yijun Yang*, Wanqiu Long, Deyi Xiong, Victor Gutierrez Basulto, Jeff Z. Pan NAACL 2025 [paper] [code]Large language models (LLMs) have demonstrated immense potential across various tasks. However, research for exploring and improving the capabilities of LLMs in interpreting graph structures remains limited. To address this gap, we conduct a comprehensive evaluation of prompting current open-source LLMs on graph-to-text generation tasks. Although we explored the optimal prompting strategies and proposed a novel and effective diversity-difficulty-based few-shot sample selection method, we found that the improvements from tuning-free approaches were incremental, as LLMs struggle with planning on complex graphs, particularly those with a larger number of triplets. To further improve LLMs in planning with graph sequences and grounding in truth, we introduce a new graph-to-text dataset, PlanGTG, annotated with two sub-tasks: reordering and attribution. Through extensive automatic and human evaluations, we demonstrate significant improvements in the quality of generated text from both few-shot learning and fine-tuning perspectives using the PlanGTG dataset. Our study paves the way for new research directions in graph-to-text generation. |

|
Xiongtao Zhou*, Jie He* , Lanyu Chen, Jingyu li, Haojing Chen, Victor Gutierrez Basulto, Jeff Z. Pan, Hanjie Chen NAACL 2025 [paper] [code]Multimodal Chain of Thought (MCoT) is a popular prompting strategy for improving the performance of multimodal large language models (MLLMs) across a range of complex reasoning tasks. Despite its popularity, there is a notable absence of automated methods for evaluating the quality of reasoning steps in MCoT. To address this gap, we propose Multimodal Chain-of-Thought Evaluation (MiCEval), a framework designed to assess the correctness of reasoning chains by evaluating the quality of both the description and each reasoning step. The evaluation of the description component focuses on the accuracy of the image descriptions, while the reasoning step evaluates the quality of each step as it is conditionally generated based on the preceding steps. MiCEval is built upon a fine-grained dataset with annotations that rate each step according to correctness, relevance, and informativeness. Extensive experiments on four state-of-the-art MLLMs show that step-wise evaluations using MiCEval align more closely with human judgments compared to existing methods based on cosine similarity or fine-tuning approaches. |
|
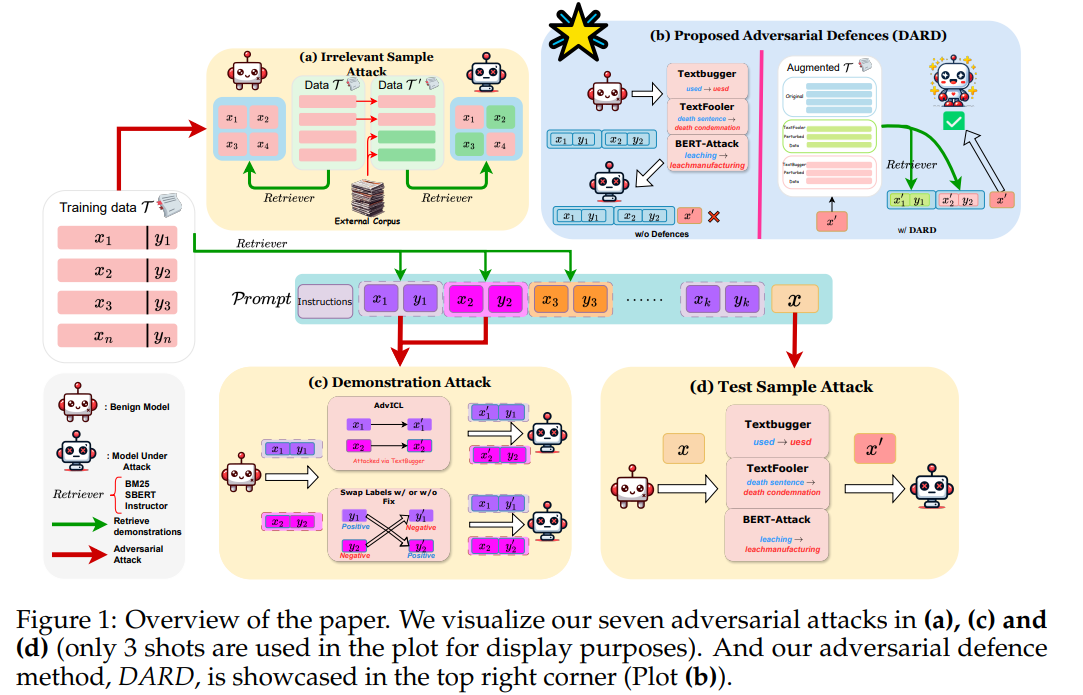
Simon Chi Lok Yu*, Jie He* , Pasquale Minervini, Jeff Z. Pan COLM 2024 [paper] [code]With the emergence of large language models, such as LLaMA and OpenAI GPT-3, In-Context Learning (ICL) gained significant attention due to its effectiveness and efficiency. However, ICL is very sensitive to the choice, order, and verbaliser used to encode the demonstrations in the prompt. Retrieval-Augmented ICL methods try to address this problem by leveraging retrievers to extract semantically related examples as demonstrations. While this approach yields more accurate results, its robustness against various types of adversarial attacks, including perturbations on test samples, demonstrations, and retrieved data, remains under-explored. Our study reveals that retrieval-augmented models can enhance robustness against test sample attacks, outperforming vanilla ICL with a 4.87% reduction in Attack Success Rate (ASR); however, they exhibit overconfidence in the demonstrations, leading to a 2% increase in ASR for demonstration attacks. Adversarial training can help improve the robustness of ICL methods to adversarial attacks; however, such a training scheme can be too costly in the context of LLMs. As an alternative, we introduce an effective training-free adversarial defence method, DARD, which enriches the example pool with those attacked samples. We show that DARD yields improvements in performance and robustness, achieving a 15% reduction in ASR over the baselines. |
|
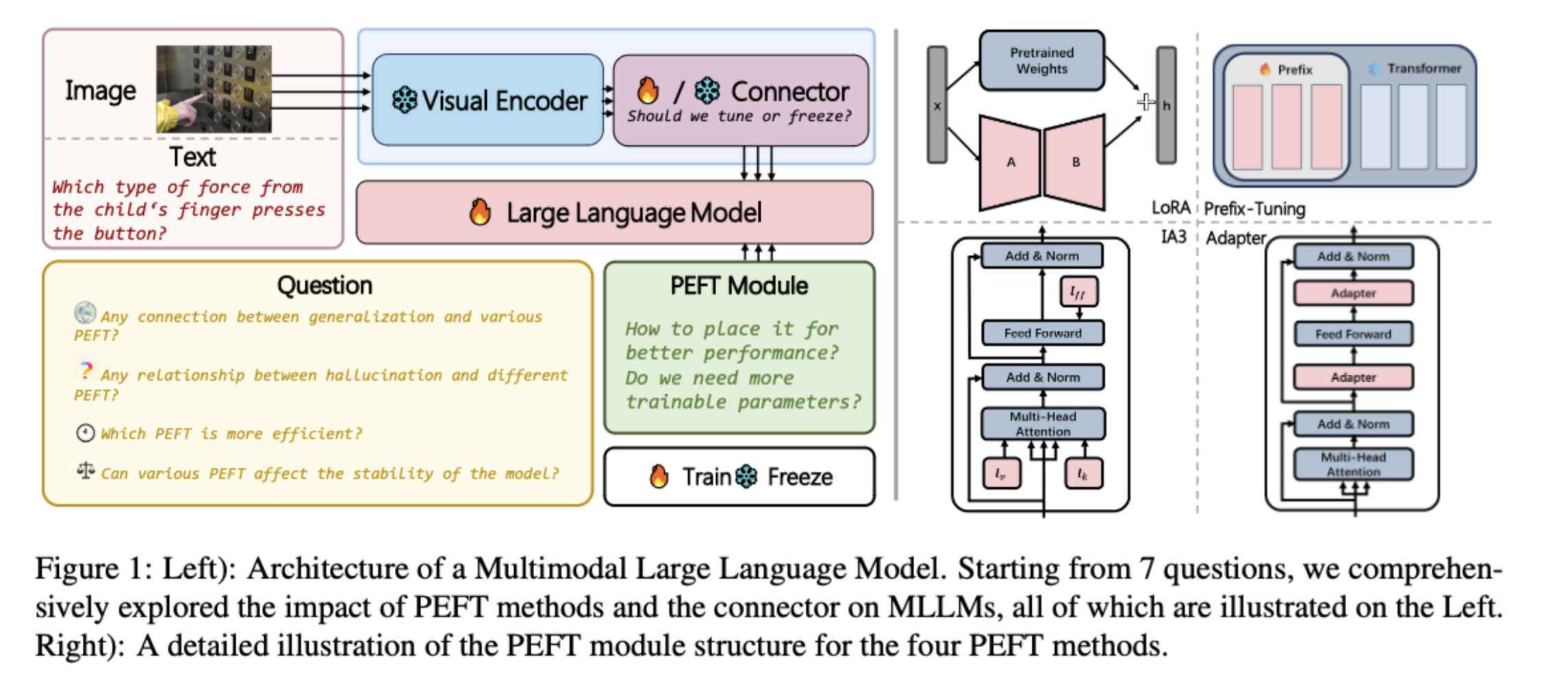
Xiongtao Zhou*, Jie He* , Yuhua Ke, Guangyao Zhu, Victor Gutierrez Basulto, Jeff Z. Pan ACL 2024 finding [paper] [code]Multimodal Large Language Models (MLLMs) fine-tuned with multimodal instruction-following data have demonstrated formidable capabilities in multimodal tasks. However, fine-tuning all parameters of MLLMs has become challenging due to the rapid growth of the overall model's parameters. To address this issue, we study Parameter-Efficient Fine-Tuning (PEFT) methods for MLLMs. We aim to identify effective methods for enhancing performance in scenarios where only a limited number of parameters are trained. This paper conducts empirical studies that employ four widely used PEFT methods to fine-tune the LLM component of open-source MLLMs. We present a comprehensive analysis that encompasses various aspects, including the impact of PEFT methods on various models, parameters and location of PEFT module, fine-tuning data scale, model stability based on PEFT method, MLLM's generalization, and hallucination. We evaluated four PEFT methods on seven datasets from two different categories, unseen and seen datasets. Across all experiments, we show that the adapter is the best-performing PEFT method in various aspects. At the same time, fine-tuning the connector layers leads to improved performance in most MLLMs. |
|
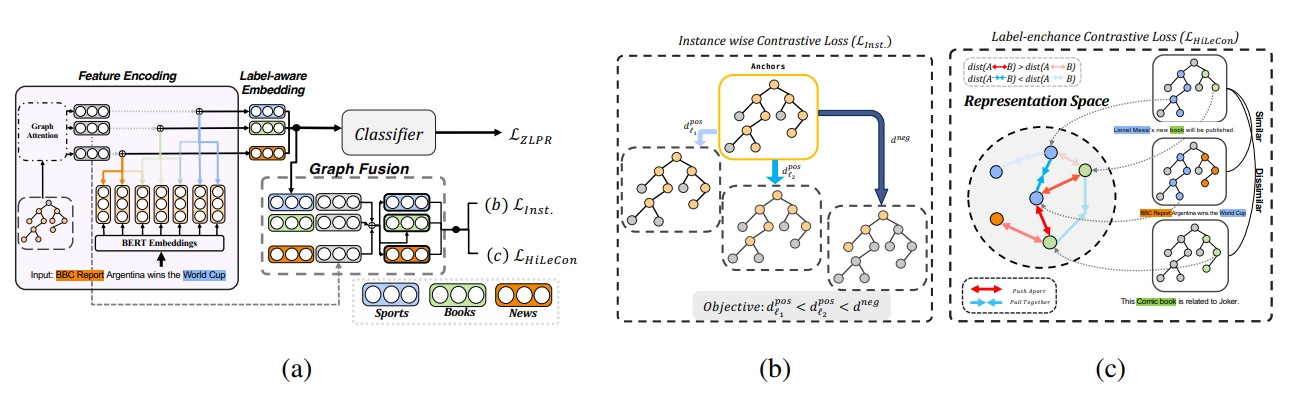
Simon Chi Lok U*, Jie He*, Victor Gutierrez-Basulto and Jeff Z. Pan EMNLP 2023 finding [paper] [code]Hierarchical multi-label text classification (HMTC) aims at utilizing a label hierarchy in multi-label classification. Recent approaches to HMTC deal with the problem of imposing an over-constrained premise on the output space by using contrastive learning on generated samples in a semi-supervised manner to bring text and label embeddings closer. However, the generation of samples tends to introduce noise as it ignores the correlation between similar samples in the same batch. One solution to this issue is supervised contrastive learning, but it remains an underexplored topic in HMTC due to its complex structured labels. To overcome this challenge, we propose HJCL, a Hierarchy-aware Joint Supervised Contrastive Learning method that bridges the gap between supervised contrastive learning and HMTC. Specifically, we employ both instance-wise and label-wise contrastive learning techniques and carefully construct batches to fulfill the contrastive learning objective. Extensive experiments on four multi-path HMTC datasets demonstrate that HJCL achieves promising results and the effectiveness of Contrastive Learning on HMTC. |
|
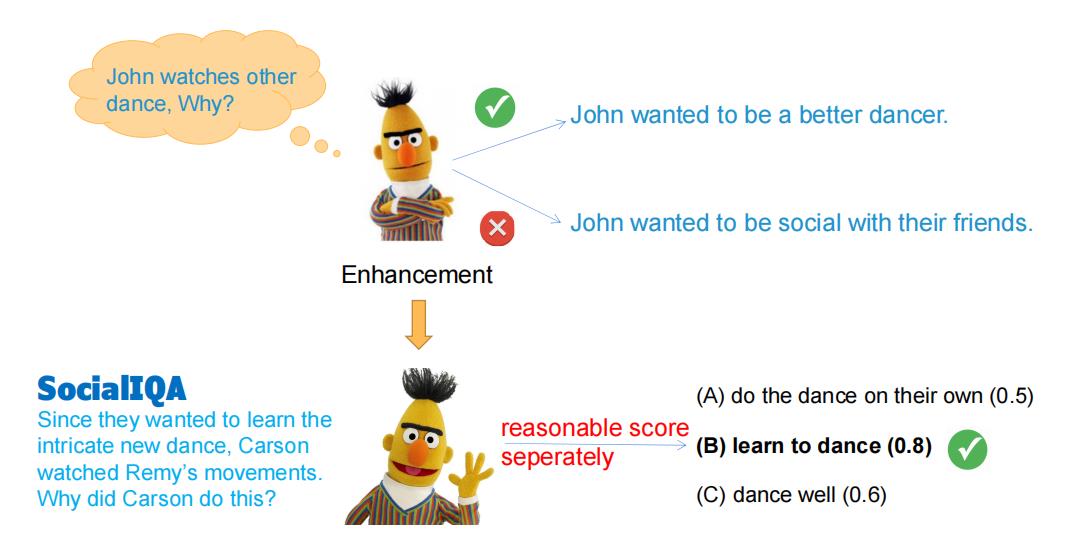
Jie He, Simon Chi Lok U, Victor Gutierrez-Basulto and Jeff Z. Pan ACL 2023 [paper] [code]Unsupervised commonsense reasoning (UCR) is becoming increasingly popular as the construction of commonsense reasoning datasets is expensive, and they are inevitably limited in their scope. A popular approach to UCR is to fine-tune language models with external knowledge (e.g., knowledge graphs), but this usually requires a large number of training examples. In this paper, we propose to transform the downstream multiple choice question answering task into a simpler binary classification task by ranking all candidate answers according to their reasonableness. To this end, for training the model, we convert the knowledge graph triples into reasonable and unreasonable texts. Extensive experimental results show the effectiveness of our approach on various multiple choice question answering benchmarks. Furthermore, compared with existing UCR approaches using KGs, ours is less data hungry. |
|
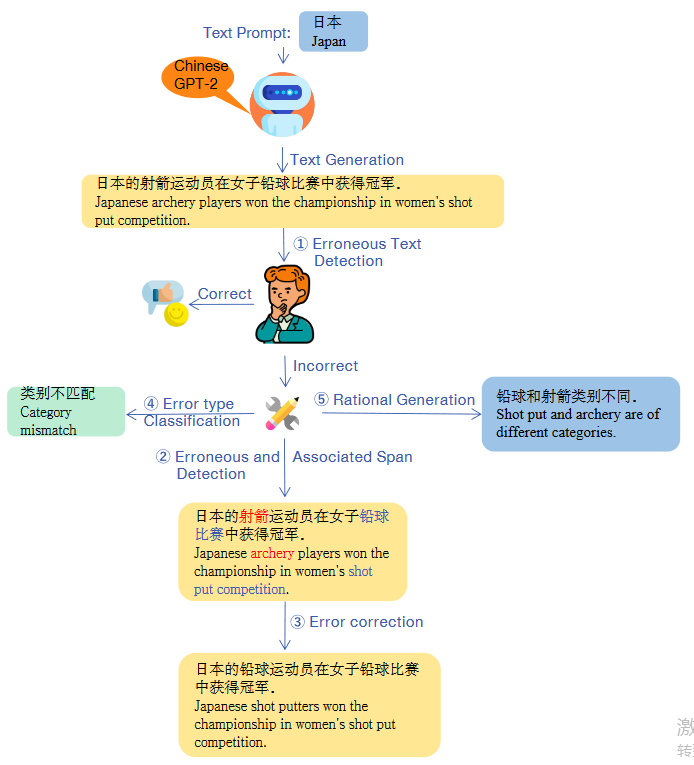
Jie He*, Bo peng*, Yi Liao, Qun Liu and Deyi Xiong ACL 2021 [paper] [dataset]In order to deeply understand the capability of pretrained language models in text generation and conduct a diagnostic evaluation, we propose TGEA. We use carefully selected prompt words to guide GPT-2 to generate candidate sentences, from which we select 47K for error annotation. We create an error taxonomy to cover 24 types of errors occurring in these erroneous sentences according to the nature of errors with respect to linguistics and knowledge (e.g., commonsense). Each error is hence manually labeled with comprehensive annotations, including the span of the error, the associated span, minimal correction to the error, the type of the error, and rationale behind the error. Furthermore, we use TGEA as a benchmark dataset and propose a series of automatic diagnosis tasks, including error detection, error type classification, associated span detection, error rationale generation, to further promote future study on the automatic error detection and correction on texts generated by pretrained language models. |

|
Jie He*, Tao Wang*, Deyi Xiong and Qun Liu EMNLP 2020 finding [paper] [dataset]In this paper, we present a test suite to evaluate the commonsense reasoning capability of neural machine translation. The test suite consists of three test sets, covering lexical and contextless/contextual syntactic ambiguity that requires commonsense knowledge to resolve. We manually create 1,200 triples, each of which contain a source sentence and two contrastive translations. We conduct extensive experiments on the test suite to evaluate commonsense reasoning in neural machine translation and investigate factors that have impact on this capability. Our experiments and analyses demonstrate that neural machine translation performs poorly on commonsense reasoning. |
|
I love philosophy. My favorite philosopher is Nietzsche, and I also enjoy reading Kant's Critique of Pure Reason. I hope to explore more studies combining linguistics and philosophy such as Wittgenstein's language games in the future. I am open to academic collaborations and please drop me an email if you are interested in collaborating with me! |
|
|
|
Updated at Sep. 2022
Thanks Jon Barron for this amazing template
|